
BP-网络可谓是机器学习领域的劝退哥,让人觉得难以亲近,其实理解之后会发现它和线性回归、逻辑回归一样,只是做了很简单的事情
那么,如何表示BP-网络才能让人更好地理解呢?
1)概念表示得是否易于理解,概念是给人看的,越容易理解越好
2)必须解释正向和反向传播在干嘛?为什么要进行反向传播?
3)应从最简单的神经网络开始,参数少,好记,不会眼花缭乱
4)公式、参数的表示和含义都要清楚,尤其是上标、下标
结合上面这几点,以解决二元分类问题为例,我们来看看BP-网络究竟做了什么
假设样本只有一个特征,一个标签,用(x,y)来表示一个样本
神经元
神经元由两个部分组成,一个是线性模型,另一个是激活函数,一般根据实际应用选择不同的激活函数
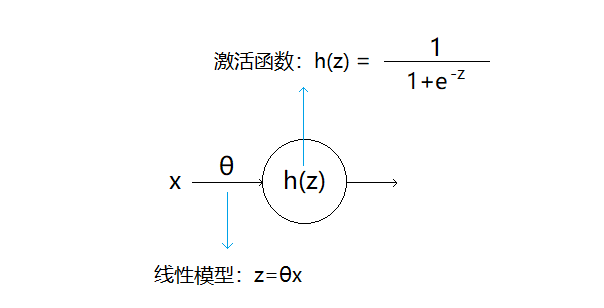
这是一个最简单的神经元:
1)有一个输入x,表示样本的一个特征(通常还有一个偏置项,我们将其忽略,因为它不影响理解)
2)设z为线性模型的输出,θ为参数
3)以sigmoid函数作为激活函数可以得到神经元的输出h(z)
没错,实际上一个神经元所做的事情和最简单的逻辑回归模型没有任何区别,但是当样本特征的数量逐渐增加时,在逻辑回归中我们常常采用将特征组合的方式构成一个多项式模型,而这将导致大量的参数需要处理,效率极低,这也是为何我们要使用神经网络的原因,就好比现在要用性能更好的多核处理器代替单核处理器了 为什么要使用神经网络?
神经网络
神经网络有三个层级,输入层、隐藏层和输出层
1)输入层的神经元读入样本特征且不做任何处理,神经元的个数取决于样本特征的数目
2)输出层表示分类的结果,对于多元分类(类别≥3),神经元的个数取决于类别的数目
3)输入层和输出层有且只有一层,而隐藏层可以有多层,每一层对上一层传递来的数据进行处理;隐藏层>1时,确保每个隐藏层的神经元个数相同;神经元的个数一般来说在不超过计算能力的情况下越多越好
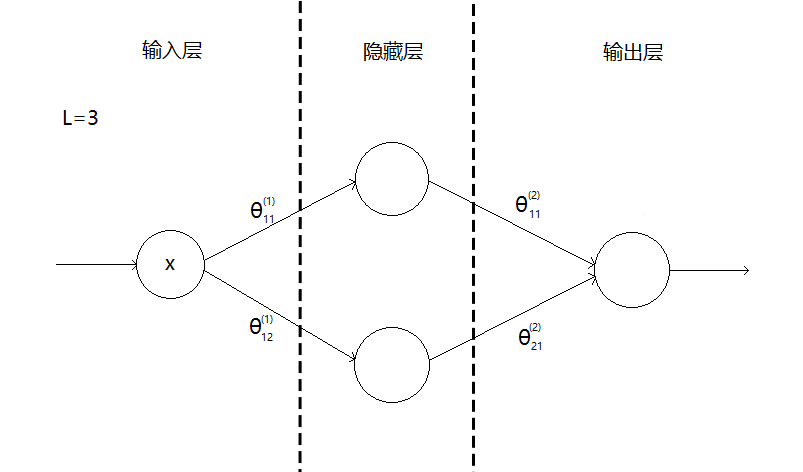
这是一个三层的神经网络:
$$
θ^{(k)}_{ij}表示第k层第i个神经元映射到第k+1层第j个神经元的参数
$$
正向和反向传播
万事具备,那么,正向和反向传播究竟做了什么?
如果要类比线性回归,那么正向传播就是在计算预测值ŷ,反向传播就是用预测值ŷ减去样本值y得到损失函数,再对损失函数求导得到梯度,使用梯度下降法更新参数
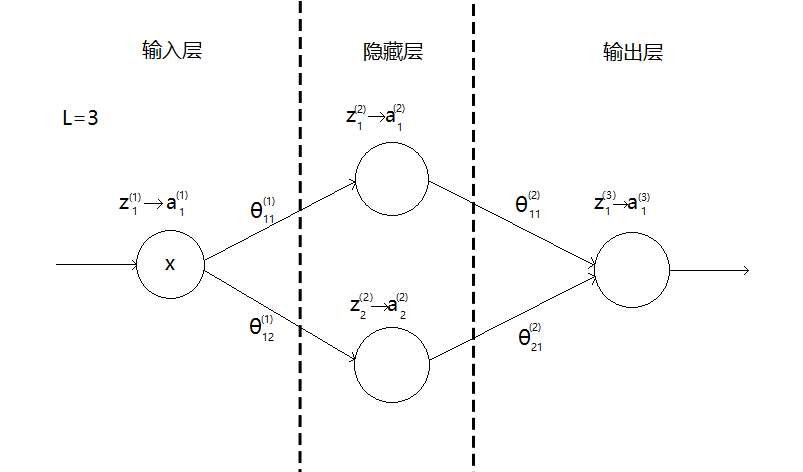
$$
a^{(i)}_j表示第i层第j个神经元的输出
$$
$$
z^{(i)}_j表示第i层第j个神经元的输入
$$
正向传播:
第一层:
$$
a^{(1)} _1=z^{(1)} _1=x
$$
第二层:
$$
z^{(2)} _1=θ^{(1)} _{11}a^{(1)} _1=θ^{(1)} _{11}x
$$
$$
a^{(2)} _1=h(z^{(2)} _1)=\frac {1}{1+e ^{ -z^{(2)} _1} }
$$
$$
z^{(2)} _2=θ^{(1)} _{12}a^{(1)} _1=θ^{(1)} _{21}x
$$
$$
a^{(2)} _2=h(z^{(2)} _2)=\frac {1}{1+e ^{ -z^{(2)} _2} }
$$
第三层:
$$
z^{(3)} _1=θ^{(2)} _{11}a^{(2)} _1+θ^{(2)} _{21}a^{(2)} _2
$$
$$
a^{(3)} _1=h(z^{(3)} _1)=\frac {1}{1+e ^{ -z^{(3)} _1} }
$$
反向传播:
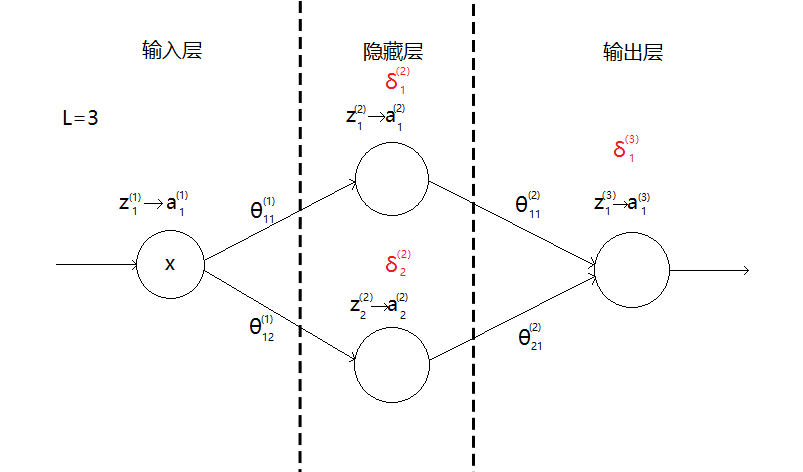
$$
δ^{(i)}_j表示第i层第j个神经元的误差
$$
由交叉熵损失函数:
$$
L(a^{(3)} _1,y)=-[yloga^{(3)} _1+(1-y)log(1-a^{(3)} _1)]
$$
使用梯度下降法更新隐藏层与输出层间的参数,其中α为学习率
$$
θ^{(2)} _{11}=θ^{(2)} _{11}-α\frac {∂L(a^{(3)} _1,y)}{∂θ^{(2)} _{11}}
$$
$$
θ^{(2)} _{21}=θ^{(2)} _{21}-α\frac {∂L(a^{(3)} _1,y)}{∂θ^{(2)} _{21}}
$$
我们只详细讨论第一个参数,由
$$
L(a^{(3)} _1,y)=-[yloga^{(3)} _1+(1-y)log(1-a^{(3)} _1)]
$$
$$
a^{(3)} _1=h(z^{(3)} _1)=\frac {1}{1+e^ { -z^{(3)} _1} }
$$
$$
z^{(3)} _1=θ^{(2)} _{11}a^{(2)} _1+θ^{(2)} _{21}a^{(2)} _2
$$
根据链式求导法则,可得
$$
\frac {∂L(a^{(3)} _1,y)}{∂θ^{(2)} _{11}}=\frac {∂L(a^{(3)} _1,y)}{∂a^{(3)} _1} \frac {∂a^{(3)} _1}{∂z^{(3)} _1} \frac {∂z^{(3)} _1}{∂θ^{(2)} _{11}}
$$
$$
\frac {∂L(a^{(3)} _1,y)}{∂a^{(3)} _1}=-(\frac {y}{a^{(3)} _1}-\frac {1-y}{1-a^{(3)} _1})=-\frac {y(1-a^{(3)} _1)-(1-y)a^{(3)} _1}{a^{(3)} _1(1-a^{(3)} _1)}=\frac {a^{(3)} _1-y}{a^{(3)} _1(1-a^{(3)} _1)}
$$
$$
\frac {∂a^{(3)} _1}{∂z^{(3)} _1}=a^{(3)} _1(1-a^{(3)} _1)
$$
$$
\frac {∂z^{(3)} _1}{∂θ^{(2)} _{11}}=a^{(2)} _1
$$
故
$$
\frac {∂L(a^{(3)} _1,y)}{∂θ^{(2)} _{11}}=(a^{(3)} _1-y)a^{(2)} _1
$$
$$
θ^{(2)} _{11}=θ^{(2)} _{11}-α(a^{(3)} _1-y)a^{(2)} _1
$$
同理可得
$$
θ^{(2)} _{21}=θ^{(2)} _{21}-α(a^{(3)} _1-y)a^{(2)} _2
$$
接下来更新输入层与隐藏层间的参数
$$
θ^{(1)} _{11}=θ^{(1)} _{11}-α\frac {∂L(a^{(3)} _1,y)}{∂θ^{(1)} _{11}}
$$
$$
θ^{(1)} _{12}=θ^{(1)} _{12}-α\frac {∂L(a^{(3)} _1,y)}{∂θ^{(1)} _{12}}
$$
由
$$
z^{(3)} _1=θ^{(2)} _{11}a^{(2)} _1+θ^{(2)} _{21}a^{(2)} _2
$$
$$
a^{(2)} _1=h(z^{(2)} _1)=\frac {1}{1+e ^{ -z^{(2)} _1} }
$$
$$
z^{(2)} _1=θ^{(1)} _{11}a^{(1)} _1=θ^{(1)} _{11}x
$$
根据链式求导法则
$$
\frac {∂L(a^{(3)} _1,y)}{∂θ^{(1)} _{11}}=\frac {∂L(a^{(3)} _1,y)}{∂a^{(3)} _1} \frac {∂a^{(3)} _1}{∂z^{(3)} _1} \frac {∂z^{(3)} _1}{∂a^{(2)} _{1}} \frac {∂a^{(2)} _1}{∂z^{(2)} _1} \frac {∂z^{(2)} _1}{∂θ^{(1)} _{11}}
$$
$$
\frac {∂L(a^{(3)} _1,y)}{∂a^{(3)} _1}=\frac {a^{(3)} _1-y}{a^{(3)} _1(1-a^{(3)} _1)}
$$
$$
\frac {∂a^{(3)} _1}{∂z^{(3)} _1}=a^{(3)} _1(1-a^{(3)} _1)
$$
$$
\frac {∂z^{(3)} _1}{∂a^{(2)} _1}=θ^{(2)} _{11}
$$
$$
\frac {∂a^{(2)} _1}{∂z^{(2)} _1}=a^{(2)} _1(1-a^{(2)} _1)
$$
$$
\frac {∂z^{(2)} _1}{∂θ^{(1)} _{11}}=x
$$
可得
$$
\frac {∂L(a^{(3)} _1,y)}{∂θ^{(1)} _{11}}=(a^{(3)} _1-y)a^{(2)} _1(1-a^{(2)} _1)θ^{(2)} _{11}x
$$
$$
θ^{(1)} _{11}=θ^{(1)} _{11}-α(a^{(3)} _1-y)a^{(2)} _1(1-a^{(2)} _1)θ^{(2)} _{11}x
$$
同理
$$
\frac {∂L(a^{(3)} _1,y)}{∂θ^{(1)} _{12}}=(a^{(3)} _1-y)a^{(2)} _2(1-a^{(2)} _2)θ^{(2)} _{21}x
$$
$$
θ^{(1)} _{12}=θ^{(1)} _{12}-α(a^{(3)} _1-y)a^{(2)} _2(1-a^{(2)} _2)θ^{(2)} _{21}x
$$
结束了?这些式子看上去十分繁琐
没错,我们还有误差δ没有介绍
误差δ
为什么要放在最后来说?这是因为我们往往把损失函数和误差当成一回事,实则不然,误差是为了方便运算而人为定义的

$$
δ^{(i)}_j表示第i层第j个神经元的误差
$$
在这个例子中:
$$
δ^{(3)} _1=a^{(3)} _1-y
$$
$$
δ^{(2)} _1=(a^{(3)} _1-y)a^{(2)} _1(1-a^{(2)} _1)θ^{(2)} _{11}=δ^{(3)} _1h’(z^{(2)} _1)θ^{(2)} _{11}
$$
$$
δ^{(2)} _2=(a^{(3)} _1-y)a^{(2)} _2(1-a^{(2)} _2)θ^{(2)} _{21}=δ^{(3)} _1h’(z^{(2)} _2)θ^{(2)} _{21}
$$
事实上,不管神经网络有多少层,隐藏层每个神经元的误差都可以用下面这个公式计算:
$$
δ^{(i)} _j=\sum _ {k=1}^m δ^{(i+1)} _k h’(z^{(i)} _j) θ^{(i)} _{jk}
$$
其中,m为下层神经元的个数
而输出层的误差等于正向传播的输出值与真实值之差
很多人问这个公式是怎么来的,我想这可能是在使用更复杂的神经网络去推导时,在求梯度的过程中发现所有梯度都具有相同形式的项,于是将其提出来,经过证明后,定义为误差,至少我是这么理解的
最后,回到我们的例子,我们所有更新参数的式子就变成了这样:
$$
θ^{(2)} _{11}=θ^{(2)} _{11}-αδ^{(3)} _1a^{(2)} _1
$$
$$
θ^{(2)} _{21}=θ^{(2)} _{21}-αδ^{(3)} _1a^{(2)} _2
$$
$$
θ^{(1)} _{11}=θ^{(1)} _{11}-αδ^{(2)} _1x
$$
$$
θ^{(1)} _{12}=θ^{(1)} _{12}-αδ^{(2)} _2x
$$
可以看到,在定义误差之后,所有更新参数的式子也具有了相同的形式:
$$
θ^{(k)} _{ij}=θ^{(k)} _{ij}-αδ^{(k+1)} _ja^{k} _i
$$
在神经网络中,很多时候用权重w代替参数θ来表示
-end-
本文链接: https://ga-lin.cn/2020/04/07/BP-网络与反向传播算法/
版权声明: 署名-非商业性使用-禁止演绎 4.0 国际(CC BY-NC-ND 4.0) 转载请保留原文链接及作者