
在此之前,我们得先重温一下回归,很多时候我们只记得公式,知道逻辑回归是怎么一回事,却忘了回归是什么,怎么来的
我们都知道逻辑回归是分类,而不是回归,那么为何会有一个回归的名称呢,个人认为其原因主要是逻辑回归本质上还是在利用回归的思想:
回归是一种归纳的思想,在深度学习领域,就是从样本的数据出发,确定某些变量之间的定量关系式;这个建立数学模型并估计未知参数的过程就叫做回归分析
逻辑回归只不过是在输出上做处理,用以解决分类问题
好了,我们给出关系式:
$$
ŷ=σ(w^Tx+b)
$$
$$
σ(z)=\frac{1}{1+e^{-z}}
$$
这里我们设w和b均为一维
怎样估计w和b?我们总是希望预测值ŷ尽可能地拟合样本值y,损失函数描述了这种拟合关系,在逻辑回归中,使用交叉熵损失函数
$$
L(\hat y,y)=-[ylog\hat y+(1-y)log(1-\hat y)]
$$
我们可以将前面两个关系式代入,得到一个关于w和b的式子,而对于每一个样本都可以得到一个损失函数,设有m个样本,对这些损失函数求和得到一个成本函数:
$$
J(w,b)=\frac {1}{m} \sum _ {i=1}^m L(\hat y^{(i)}, y^{(i)})
$$
接下来问题变成了如何找到一组w和b,使得这个成本函数尽可能地小,可以形象地将其表示为一个“找碗底”的过程
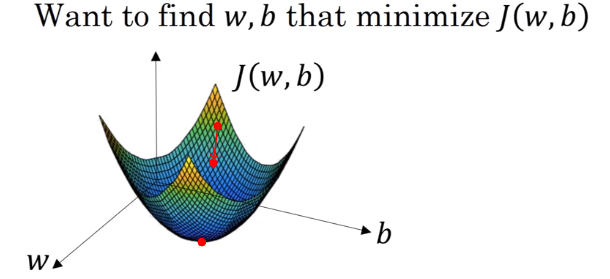
这就是梯度下降法所要做的,从初始点开始,每一次迭代都使用如下公式更新w和b,使得成本函数总是沿着最接近“碗底”的方向下降:
$$
w=w-α\frac {∂J(w,b)}{∂w}
$$
$$
b=b-α\frac {∂J(w,b)}{∂b}
$$
其中α为学习率,用以控制每一次梯度下降的步长
关于初始化w和b,几乎是任意的初始化方法都有效,因为成本函数是凸函数,无论在哪里初始化,使用梯度下降法都应该能达到”碗底“或其附近,这也是为什么选择交叉熵作为损失函数的原因,它总能得到或接近一个全局最优解
下面我们只关注w,忽略b,具体来看看梯度下降法为什么能够”找到碗底“
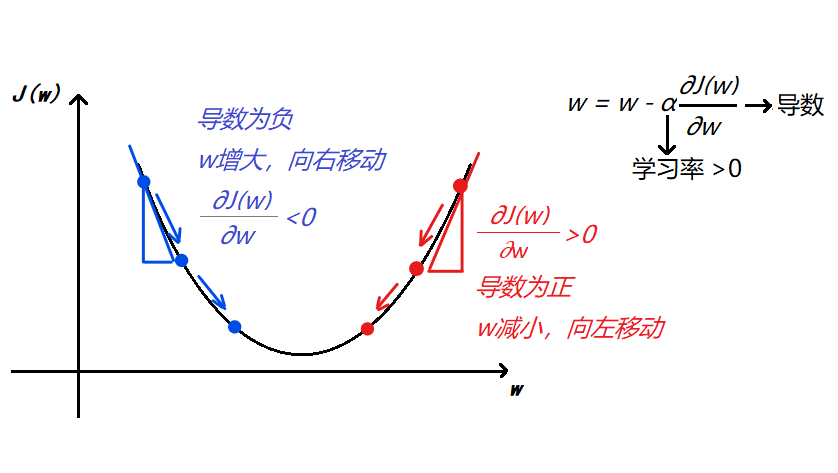
由上图可以看到,无论怎样初始化w,梯度下降法总是使w朝着成本函数减少的方向移动的
本文链接: https://ga-lin.cn/2020/01/30/逻辑回归与梯度下降法/
版权声明: 署名-非商业性使用-禁止演绎 4.0 国际(CC BY-NC-ND 4.0) 转载请保留原文链接及作者