| Cradle Waltz | Run Lads Run | Waltz in Devil's Playground |
|---|---|---|
 |
 |
 |
| Living In The One | DIARY | Post-script |
 |
 |
 |

Galin
欢迎
BP-网络与反向传播算法
BP-网络可谓是机器学习领域的劝退哥,让人觉得难以亲近,其实理解之后会发现它和线性回归、逻辑回归一样,只是做了很简单的事情
那么,如何表示BP-网络才能让人更好地理解呢?
1)概念表示得是否易于理解,概念是给人看的,越容易理解越好
2)必须解释正向和反向传播在干嘛?为什么要进行反向传播?
3)应从最简单的神经网络开始,参数少,好记,不会眼花缭乱
4)公式、参数的表示和含义都要清楚,尤其是上标、下标
结合上面这几点,以解决二元分类问题为例,我们来看看BP-网络究竟做了什么
假设样本只有一个特征,一个标签,用(x,y)来表示一个样本
神经元
神经元由两个部分组成,一个是线性模型,另一个是激活函数,一般根据实际应用选择不同的激活函数
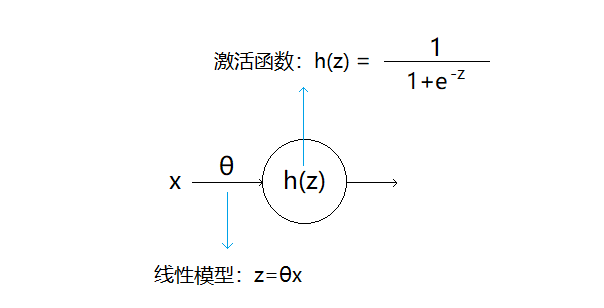
这是一个最简单的神经元:
1)有一个输入x,表示样本的一个特征(通常还有一个偏置项,我们将其忽略,因为它不影响理解)
2)设z为线性模型的输出,θ为参数
3)以sigmoid函数作为激活函数可以得到神经元的输出h(z)
没错,实际上一个神经元所做的事情和最简单的逻辑回归模型没有任何区别,但是当样本特征的数量逐渐增加时,在逻辑回归中我们常常采用将特征组合的方式构成一个多项式模型,而这将导致大量的参数需要处理,效率极低,这也是为何我们要使用神经网络的原因,就好比现在要用性能更好的多核处理器代替单核处理器了 为什么要使用神经网络?
神经网络
神经网络有三个层级,输入层、隐藏层和输出层
1)输入层的神经元读入样本特征且不做任何处理,神经元的个数取决于样本特征的数目
2)输出层表示分类的结果,对于多元分类(类别≥3),神经元的个数取决于类别的数目
3)输入层和输出层有且只有一层,而隐藏层可以有多层,每一层对上一层传递来的数据进行处理;隐藏层>1时,确保每个隐藏层的神经元个数相同;神经元的个数一般来说在不超过计算能力的情况下越多越好
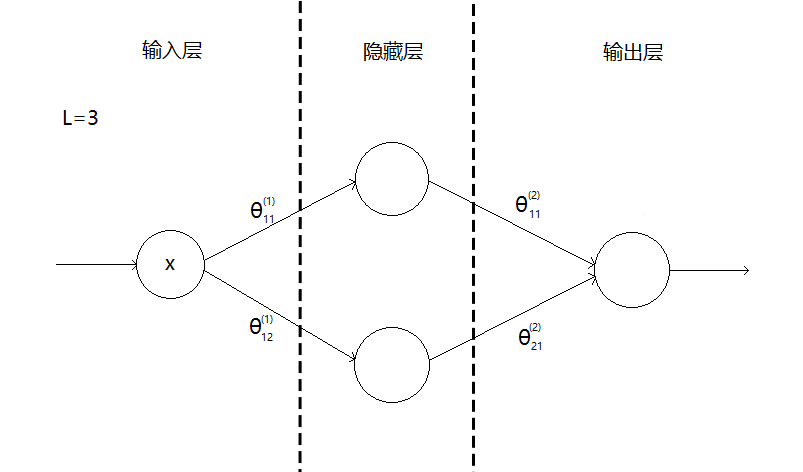
这是一个三层的神经网络:
$$
θ^{(k)}_{ij}表示第k层第i个神经元映射到第k+1层第j个神经元的参数
$$
正向和反向传播
万事具备,那么,正向和反向传播究竟做了什么?
如果要类比线性回归,那么正向传播就是在计算预测值ŷ,反向传播就是用预测值ŷ减去样本值y得到损失函数,再对损失函数求导得到梯度,使用梯度下降法更新参数
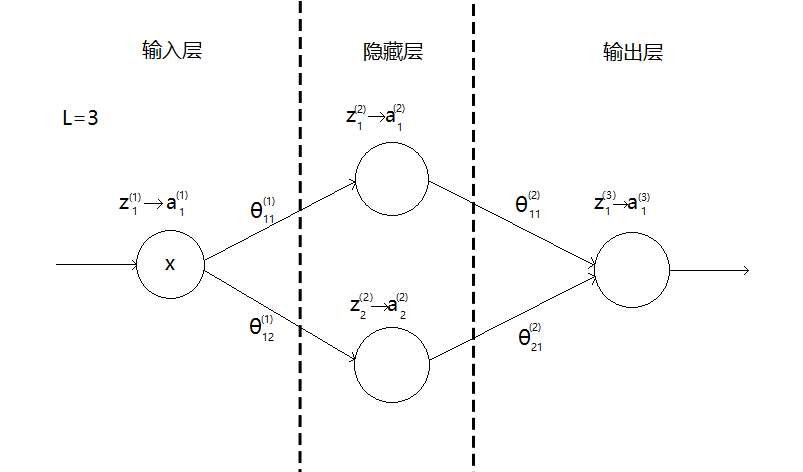
$$
a^{(i)}_j表示第i层第j个神经元的输出
$$
$$
z^{(i)}_j表示第i层第j个神经元的输入
$$
正向传播:
第一层:
$$
a^{(1)} _1=z^{(1)} _1=x
$$
第二层:
$$
z^{(2)} _1=θ^{(1)} _{11}a^{(1)} _1=θ^{(1)} _{11}x
$$
$$
a^{(2)} _1=h(z^{(2)} _1)=\frac {1}{1+e ^{ -z^{(2)} _1} }
$$
$$
z^{(2)} _2=θ^{(1)} _{12}a^{(1)} _1=θ^{(1)} _{21}x
$$
$$
a^{(2)} _2=h(z^{(2)} _2)=\frac {1}{1+e ^{ -z^{(2)} _2} }
$$
第三层:
$$
z^{(3)} _1=θ^{(2)} _{11}a^{(2)} _1+θ^{(2)} _{21}a^{(2)} _2
$$
$$
a^{(3)} _1=h(z^{(3)} _1)=\frac {1}{1+e ^{ -z^{(3)} _1} }
$$
反向传播:
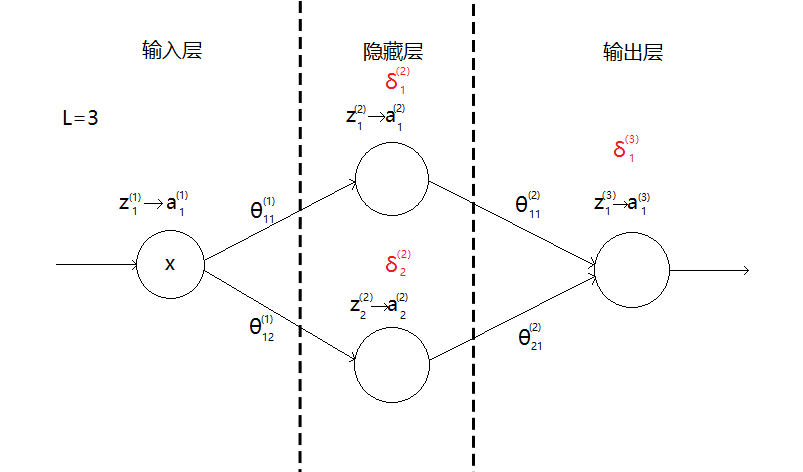
$$
δ^{(i)}_j表示第i层第j个神经元的误差
$$
由交叉熵损失函数:
$$
L(a^{(3)} _1,y)=-[yloga^{(3)} _1+(1-y)log(1-a^{(3)} _1)]
$$
使用梯度下降法更新隐藏层与输出层间的参数,其中α为学习率
$$
θ^{(2)} _{11}=θ^{(2)} _{11}-α\frac {∂L(a^{(3)} _1,y)}{∂θ^{(2)} _{11}}
$$
$$
θ^{(2)} _{21}=θ^{(2)} _{21}-α\frac {∂L(a^{(3)} _1,y)}{∂θ^{(2)} _{21}}
$$
我们只详细讨论第一个参数,由
$$
L(a^{(3)} _1,y)=-[yloga^{(3)} _1+(1-y)log(1-a^{(3)} _1)]
$$
$$
a^{(3)} _1=h(z^{(3)} _1)=\frac {1}{1+e^ { -z^{(3)} _1} }
$$
$$
z^{(3)} _1=θ^{(2)} _{11}a^{(2)} _1+θ^{(2)} _{21}a^{(2)} _2
$$
根据链式求导法则,可得
$$
\frac {∂L(a^{(3)} _1,y)}{∂θ^{(2)} _{11}}=\frac {∂L(a^{(3)} _1,y)}{∂a^{(3)} _1} \frac {∂a^{(3)} _1}{∂z^{(3)} _1} \frac {∂z^{(3)} _1}{∂θ^{(2)} _{11}}
$$
$$
\frac {∂L(a^{(3)} _1,y)}{∂a^{(3)} _1}=-(\frac {y}{a^{(3)} _1}-\frac {1-y}{1-a^{(3)} _1})=-\frac {y(1-a^{(3)} _1)-(1-y)a^{(3)} _1}{a^{(3)} _1(1-a^{(3)} _1)}=\frac {a^{(3)} _1-y}{a^{(3)} _1(1-a^{(3)} _1)}
$$
$$
\frac {∂a^{(3)} _1}{∂z^{(3)} _1}=a^{(3)} _1(1-a^{(3)} _1)
$$
$$
\frac {∂z^{(3)} _1}{∂θ^{(2)} _{11}}=a^{(2)} _1
$$
故
$$
\frac {∂L(a^{(3)} _1,y)}{∂θ^{(2)} _{11}}=(a^{(3)} _1-y)a^{(2)} _1
$$
$$
θ^{(2)} _{11}=θ^{(2)} _{11}-α(a^{(3)} _1-y)a^{(2)} _1
$$
同理可得
$$
θ^{(2)} _{21}=θ^{(2)} _{21}-α(a^{(3)} _1-y)a^{(2)} _2
$$
接下来更新输入层与隐藏层间的参数
$$
θ^{(1)} _{11}=θ^{(1)} _{11}-α\frac {∂L(a^{(3)} _1,y)}{∂θ^{(1)} _{11}}
$$
$$
θ^{(1)} _{12}=θ^{(1)} _{12}-α\frac {∂L(a^{(3)} _1,y)}{∂θ^{(1)} _{12}}
$$
由
$$
z^{(3)} _1=θ^{(2)} _{11}a^{(2)} _1+θ^{(2)} _{21}a^{(2)} _2
$$
$$
a^{(2)} _1=h(z^{(2)} _1)=\frac {1}{1+e ^{ -z^{(2)} _1} }
$$
$$
z^{(2)} _1=θ^{(1)} _{11}a^{(1)} _1=θ^{(1)} _{11}x
$$
根据链式求导法则
$$
\frac {∂L(a^{(3)} _1,y)}{∂θ^{(1)} _{11}}=\frac {∂L(a^{(3)} _1,y)}{∂a^{(3)} _1} \frac {∂a^{(3)} _1}{∂z^{(3)} _1} \frac {∂z^{(3)} _1}{∂a^{(2)} _{1}} \frac {∂a^{(2)} _1}{∂z^{(2)} _1} \frac {∂z^{(2)} _1}{∂θ^{(1)} _{11}}
$$
$$
\frac {∂L(a^{(3)} _1,y)}{∂a^{(3)} _1}=\frac {a^{(3)} _1-y}{a^{(3)} _1(1-a^{(3)} _1)}
$$
$$
\frac {∂a^{(3)} _1}{∂z^{(3)} _1}=a^{(3)} _1(1-a^{(3)} _1)
$$
$$
\frac {∂z^{(3)} _1}{∂a^{(2)} _1}=θ^{(2)} _{11}
$$
$$
\frac {∂a^{(2)} _1}{∂z^{(2)} _1}=a^{(2)} _1(1-a^{(2)} _1)
$$
$$
\frac {∂z^{(2)} _1}{∂θ^{(1)} _{11}}=x
$$
可得
$$
\frac {∂L(a^{(3)} _1,y)}{∂θ^{(1)} _{11}}=(a^{(3)} _1-y)a^{(2)} _1(1-a^{(2)} _1)θ^{(2)} _{11}x
$$
$$
θ^{(1)} _{11}=θ^{(1)} _{11}-α(a^{(3)} _1-y)a^{(2)} _1(1-a^{(2)} _1)θ^{(2)} _{11}x
$$
同理
$$
\frac {∂L(a^{(3)} _1,y)}{∂θ^{(1)} _{12}}=(a^{(3)} _1-y)a^{(2)} _2(1-a^{(2)} _2)θ^{(2)} _{21}x
$$
$$
θ^{(1)} _{12}=θ^{(1)} _{12}-α(a^{(3)} _1-y)a^{(2)} _2(1-a^{(2)} _2)θ^{(2)} _{21}x
$$
结束了?这些式子看上去十分繁琐
没错,我们还有误差δ没有介绍
误差δ
为什么要放在最后来说?这是因为我们往往把损失函数和误差当成一回事,实则不然,误差是为了方便运算而人为定义的

$$
δ^{(i)}_j表示第i层第j个神经元的误差
$$
在这个例子中:
$$
δ^{(3)} _1=a^{(3)} _1-y
$$
$$
δ^{(2)} _1=(a^{(3)} _1-y)a^{(2)} _1(1-a^{(2)} _1)θ^{(2)} _{11}=δ^{(3)} _1h’(z^{(2)} _1)θ^{(2)} _{11}
$$
$$
δ^{(2)} _2=(a^{(3)} _1-y)a^{(2)} _2(1-a^{(2)} _2)θ^{(2)} _{21}=δ^{(3)} _1h’(z^{(2)} _2)θ^{(2)} _{21}
$$
事实上,不管神经网络有多少层,隐藏层每个神经元的误差都可以用下面这个公式计算:
$$
δ^{(i)} _j=\sum _ {k=1}^m δ^{(i+1)} _k h’(z^{(i)} _j) θ^{(i)} _{jk}
$$
其中,m为下层神经元的个数
而输出层的误差等于正向传播的输出值与真实值之差
很多人问这个公式是怎么来的,我想这可能是在使用更复杂的神经网络去推导时,在求梯度的过程中发现所有梯度都具有相同形式的项,于是将其提出来,经过证明后,定义为误差,至少我是这么理解的
最后,回到我们的例子,我们所有更新参数的式子就变成了这样:
$$
θ^{(2)} _{11}=θ^{(2)} _{11}-αδ^{(3)} _1a^{(2)} _1
$$
$$
θ^{(2)} _{21}=θ^{(2)} _{21}-αδ^{(3)} _1a^{(2)} _2
$$
$$
θ^{(1)} _{11}=θ^{(1)} _{11}-αδ^{(2)} _1x
$$
$$
θ^{(1)} _{12}=θ^{(1)} _{12}-αδ^{(2)} _2x
$$
可以看到,在定义误差之后,所有更新参数的式子也具有了相同的形式:
$$
θ^{(k)} _{ij}=θ^{(k)} _{ij}-αδ^{(k+1)} _ja^{k} _i
$$
在神经网络中,很多时候用权重w代替参数θ来表示
-end-
逻辑回归与梯度下降法
在此之前,我们得先重温一下回归,很多时候我们只记得公式,知道逻辑回归是怎么一回事,却忘了回归是什么,怎么来的
我们都知道逻辑回归是分类,而不是回归,那么为何会有一个回归的名称呢,个人认为其原因主要是逻辑回归本质上还是在利用回归的思想:
回归是一种归纳的思想,在深度学习领域,就是从样本的数据出发,确定某些变量之间的定量关系式;这个建立数学模型并估计未知参数的过程就叫做回归分析
逻辑回归只不过是在输出上做处理,用以解决分类问题
好了,我们给出关系式:
$$
ŷ=σ(w^Tx+b)
$$
$$
σ(z)=\frac{1}{1+e^{-z}}
$$
这里我们设w和b均为一维
怎样估计w和b?我们总是希望预测值ŷ尽可能地拟合样本值y,损失函数描述了这种拟合关系,在逻辑回归中,使用交叉熵损失函数
$$
L(\hat y,y)=-[ylog\hat y+(1-y)log(1-\hat y)]
$$
我们可以将前面两个关系式代入,得到一个关于w和b的式子,而对于每一个样本都可以得到一个损失函数,设有m个样本,对这些损失函数求和得到一个成本函数:
$$
J(w,b)=\frac {1}{m} \sum _ {i=1}^m L(\hat y^{(i)}, y^{(i)})
$$
接下来问题变成了如何找到一组w和b,使得这个成本函数尽可能地小,可以形象地将其表示为一个“找碗底”的过程
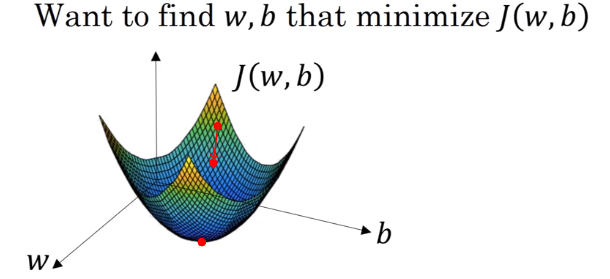
这就是梯度下降法所要做的,从初始点开始,每一次迭代都使用如下公式更新w和b,使得成本函数总是沿着最接近“碗底”的方向下降:
$$
w=w-α\frac {∂J(w,b)}{∂w}
$$
$$
b=b-α\frac {∂J(w,b)}{∂b}
$$
其中α为学习率,用以控制每一次梯度下降的步长
关于初始化w和b,几乎是任意的初始化方法都有效,因为成本函数是凸函数,无论在哪里初始化,使用梯度下降法都应该能达到”碗底“或其附近,这也是为什么选择交叉熵作为损失函数的原因,它总能得到或接近一个全局最优解
下面我们只关注w,忽略b,具体来看看梯度下降法为什么能够”找到碗底“
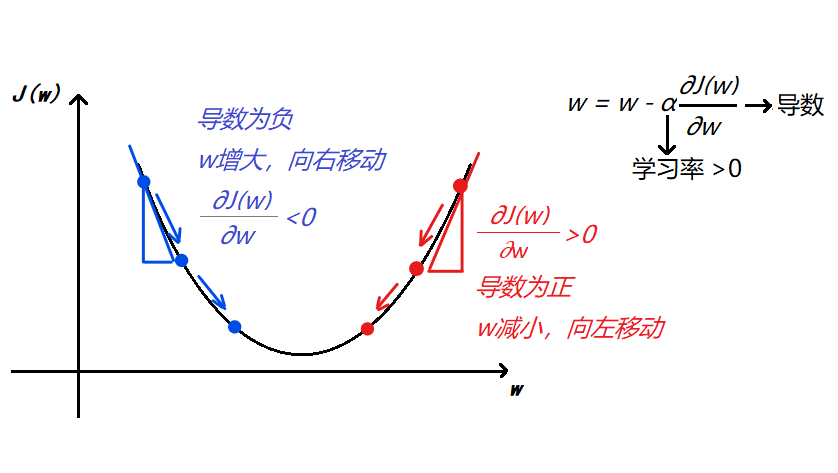
由上图可以看到,无论怎样初始化w,梯度下降法总是使w朝着成本函数减少的方向移动的
交叉熵损失函数
在理解交叉熵损失函数之前,有必要先来说一下信息熵这个概念
信息熵
信息熵可以理解为信息杂乱程度的量化描述:信息越多,概率越均等则信息熵就越大;反之,信息越单一,概率越偏向其中某一个信息,那么熵值就越小
公式如下:
$$
H(X)=-\sum _ {i=1}^n P(x^{(i)}) logP(x^{(i)})
$$
其中,
$$
-logP(x^{(i)})
$$
表示一个信息的信息量,概率越小,信息量就越大,这很好理解,比如“太阳从西边出来了”,这几乎不可能发生,如果发生了,那对于我们来说其所含的信息量是巨大的
交叉熵损失函数
先给出公式:
$$
L(\hat y,y)=-[ylog\hat y+(1-y)log(1-\hat y)]
$$
其中ŷ为预测值
我们来解释一下这个公式为什么能起作用:
对于损失函数,我们希望它越小越好
当y=1时,L(ŷ,y)=-log ŷ,则ŷ应尽可能接近于1,才能让损失函数尽可能地小
当y=0时,L(ŷ,y)=-(1-y)log(1-ŷ),则ŷ应尽可能接近于0,才能让损失函数尽可能地小
在逻辑回归中,预测值是一个概率,它表示与样本的拟合程度,而该公式既很好地表达了这种关系,也满足了损失函数的定义
最优性原理
看了很多有关最优性原理的解释,总是感觉不清晰、不透彻,以下是我个人的理解
我们先给出定义:
最优性原理 对于多阶段决策过程的最优决策序列具有如下性质:不论初始状态和初始决策如何,对于前面决策所造成的某一状态而言,其后各阶段的决策序列必须构成最优策略
它看上去很讨厌,如同与你玩文字游戏,我们单看冒号前的文字,可知:
1)首先它指出,这是一个性质,是最优决策序列的性质
2)假设我们已知这个最优决策序列
好了我们就此打住,不继续往下解读了,我们来看一个直观的例子:
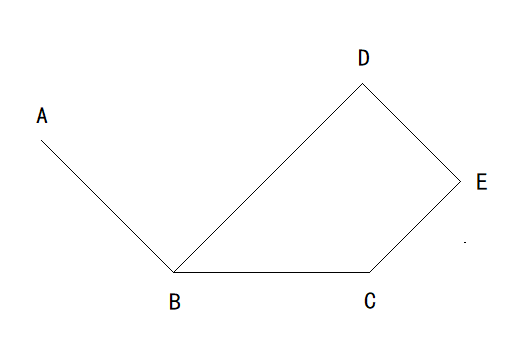
假设有地点A、B、C、D、E,火车要从A开往E,求最短路线
这显然是一个多阶段决策问题,火车每到达一个地点,必须选择下一个开往的地点
假设我们已知这个问题的最优决策序列,显然它是A->B->C->E
请一定记住,我们接下来的讨论都是基于这个假设之上的
火车到达B后,从B开往E的最短路线是什么?
我们不知道,我们现在只知道:
1)从A开往E的最短路线A->B->C->E
2)B处有两个决策:开往C或开往D
此时,冒号之后的文字起了作用,在这个问题里,它表达为:从B开往E的最短路线必须在A->B->C->E上,即B->C->E,故火车在B处选择开往C
换一个角度理解,那么最优性原理想要表达的就是:
对于多阶段决策问题,整个问题的最优决策序列,一定包含了它子问题的最优决策序列
不严谨地说就是,多阶段决策问题的整体最优解一定能使得局部最优
斜投影——学习笔记
当投射直线与投影面不垂直时,投影面得到的就是斜投影,下面我们用一个直观的例子来说明
一个直观的例子:
假设:
1)投影平面为 z=0
2)直角坐标为(0,0,1)的点P通过斜投影得到点P’
3)L为P’到坐标原点的距离
4)α为OP’与x轴正向所形成的角
5)β为投射直线与投影平面所成的角
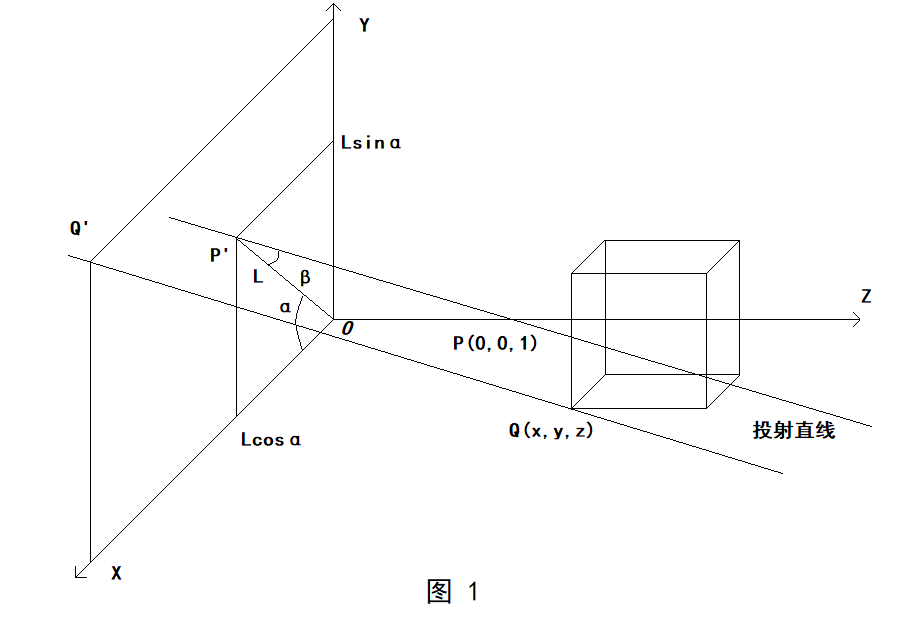
设三维空间中有直角坐标为(x,y,z)的任意一点Q’(如立方体的顶点),通过斜投影所得投影点的直角坐标为Q’(x’,y’,z’),显然 z’=0,则
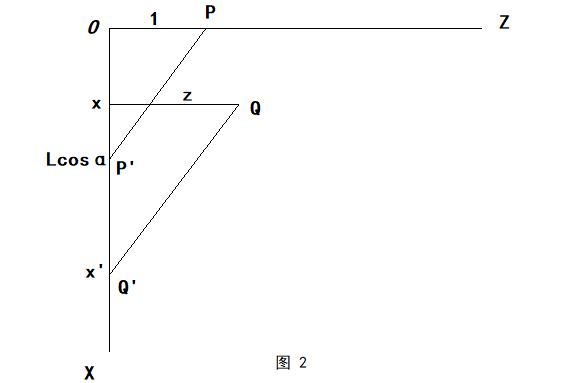
沿y轴负方向看去(如上图),可得:
$$
\frac{x’-x}{z}=\frac{Lcosα}{1}
$$
同理,沿x轴负方向看去可得:
$$
\frac{y’-y}{z}=\frac{Lsinα}{1}
$$
因此有斜投影变换公式:
$$
x’=x+z(Lcosα),y’=y+z(Lsinα)
$$
可将三维空间中任意一点斜投影至平面 z=0上
如何得到斜二测投影?
实际上,观察图 1可知,投影平面上斜投影点的位置与角β有关,而角β受到点P位置和L大小的控制
我们可以调整点P位置和L大小,使得
当tanβ=2时,即可得到斜二测投影(斜二测投影使垂直于投影面的线段长度缩短为原来的一半)
当tanβ=1时,得到斜等测投影(斜等测投影使垂直于投影面的线段仍保持长度)
这时的α角还可以不同
Welcome!
非常高兴能够搭建自己的个人博客
感谢 CodeSheep 大大的视频 手把手教你从0开始搭建自己的个人博客 |无坑版视频教程| hexo
今后将在这里记录下自己的Coding旅程🙈
Welcome!

缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true